本文最后更新于 1215 天前,其中的信息可能已经有所发展或是发生改变。
MobileNet V1
- 主要特点:把卷积拆分为Depthwise和Pointwise两部分(深度可分离卷积Separable convolution),用步长为2的卷积代替池化。
- Depthwise和Pointwise图解:
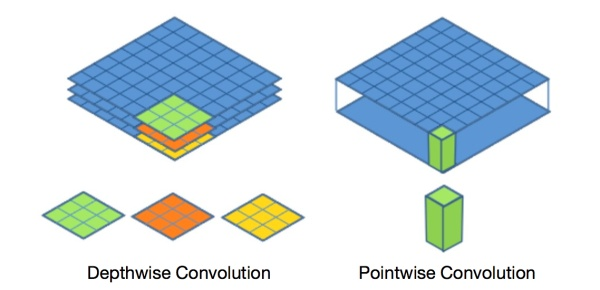
假设有$N \times H \times W \times C$的输入,普通卷积是做$k$个3×3的卷积,且same padding,$stride=1$,输出为$N \times H \times W \times k$。depthwise是将此输入分为$group=C$组,然后每组做一次卷积,相当于收集了每个channel的特征,输出依然是$N \times H \times W \times C$。pointwise是做$k$个普通的1×1卷积,相当于收集了每个点的特征。depthwise+pointwise的输出也为$N \times H \times W \times k$。
-
普通卷积和MobileNet卷积对比如下图所示。计算一下两者的参数量:
- 普通卷积为:$C \times k \times 3 \times 3$
- depthwise+pointwise:$C \times 3 \times 3 + C \times k \times 1 \times 1$
- 压缩率为$\frac{depthwise+pointwise}{conv}=\frac{1}{k} + frac{1}{3 \times 3}$

- 进一步压缩模型:引入了width multiplier,所有通道数乘以$\alpha \in (0,1]$(四舍五入),以降低模型的宽度。
MobileNet V2
- 主要特点:引入残差结构;采用linear bottenecks + inverted residual结构,先升维后降维;使用relu6(最大输出为6)激活函数,使模型在低精度计算下有更强的鲁棒性。
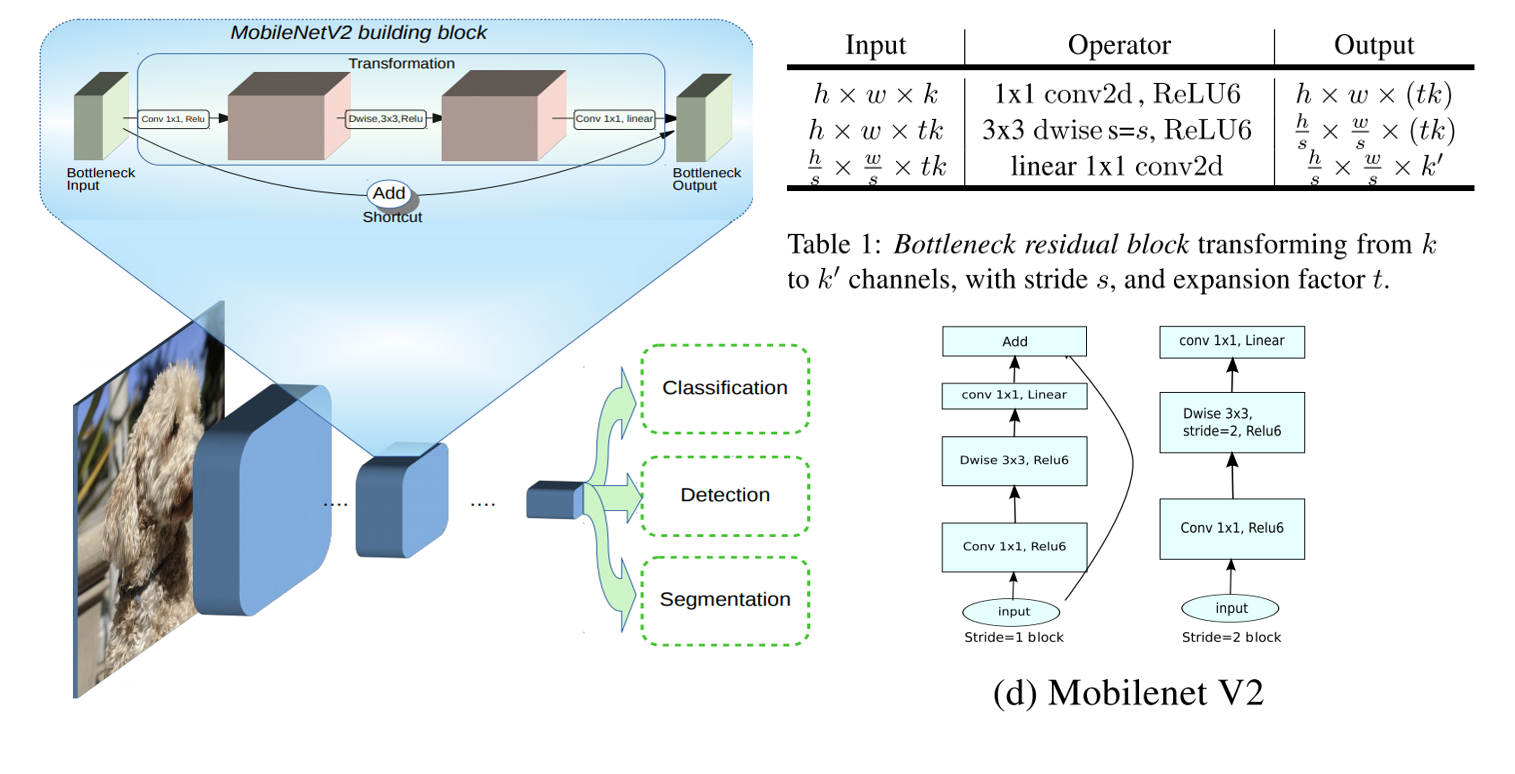
- linear bottenecks + inverted residual结构如下图所示。
- V2版本依然是使用depthwise和pointwise,不同的是在depthwise前加了一个1×1卷积来扩大通道数目扩张系数为$t$,即通道数目扩大$t$倍,以增加特征丰富性。在pointwise之后再加1×1卷积将通道数目压缩至原输入的数目。
- V2版本去掉了第二个1×1卷积之后的激活函数,称为linear bottleneck。作者认为激活函数在高维空间能够有效地增加非线性,但在地位空间会破坏特征。
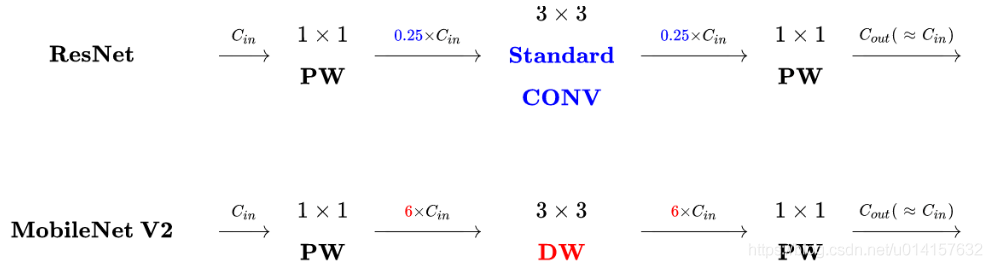
- 与残差模块的对比:
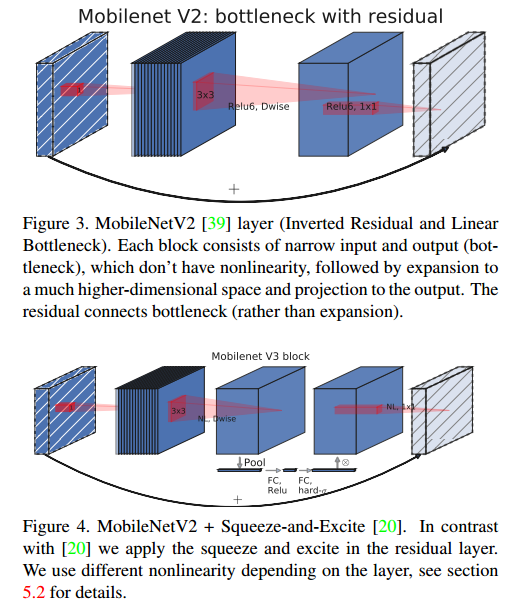
- V2网络结构:

MobileNet V3
- 主要特点:引入SE(squeeze and excitation)结构;使用hard swish激活函数;头部卷积通道数量由32变为16;V2在预测部分使用了一个bottleneck结构来提取特征,而V3用两个1×1代替了这个操作;结构用NAS技术生成
- SE轻量级注意力结构,如下图所示。在depthwise后加入SE模块,首先globalpool,然后1×1卷积将其通道压缩为原来的1/4,然后再1×1卷积扩回去,再乘以SE的输入。SE即提高了精度,同时还没有增加时间消耗。
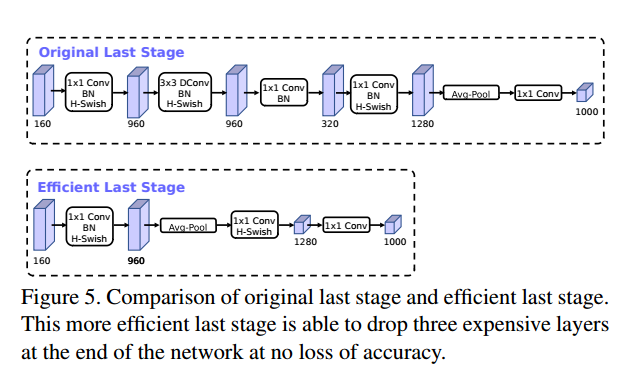
- 尾部修改:
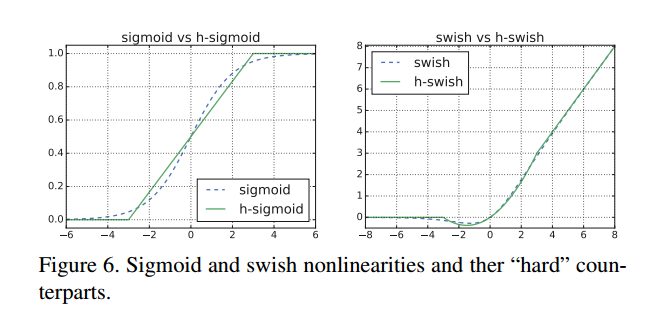
- hard swish激活函数如下所示。swish激活函数可以提高精度,但计算量比较大,作者用relu近似模拟,称为hard swish
$$ \Bbb{swich} [x]=x \cdot \sigma(x) \\
\Bbb{h-swish}[x]=x \frac{ReLU6(x+3)}{6} $$
- v2头部卷积为32x3x3,作者发现可以改为16,保证了精度且降低了延时时间。
- 网络结构搜索,借鉴了MansNet和NetAdapt,这部分以后再详细补充。
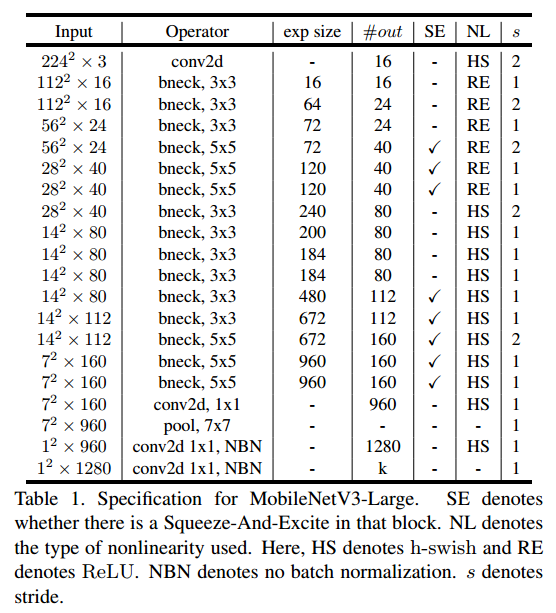
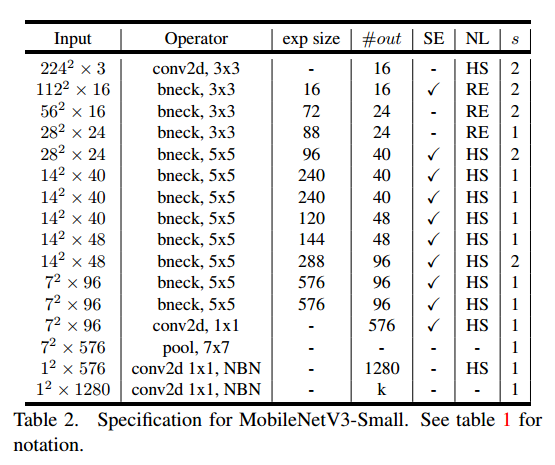
- 网络结构:
参考文献
[1] https://zhuanlan.zhihu.com/p/35405071
[2] https://blog.csdn.net/mzpmzk/article/details/82976871
[3] https://www.cnblogs.com/darkknightzh/p/9410540.html
[4] https://blog.csdn.net/DL_wly/article/details/90168883
[5] https://blog.csdn.net/Chunfengyanyulove/article/details/91358187