本文最后更新于 1226 天前,其中的信息可能已经有所发展或是发生改变。
字典树
字典树(Trie) 又称单词查找树或键树,是一种哈希树的变种。典型的应用是用于统计和排序大量的字符串(但不限于字符串),优点是可以可以最大限度地减少无畏的字符串比较,查询效率比哈希表高。Trie的核心思想是空间换时间,利用字符串的公共前缀来降低查询的时间。
比如有一个包含多个单词的列表:[‘word’, ‘work’, ‘code’, ‘coffe’],可以下面的字典树表示:
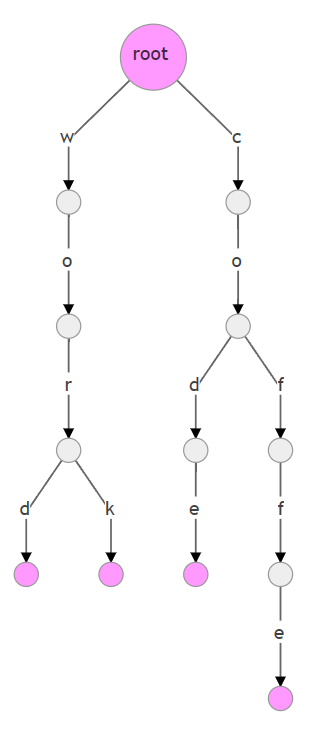
字典树的性质:
- 根节点不包含字符,除根节点外每个节点只包含一个字符
- 从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串
- 每个节点的所有子节点包含的字符串都不同
从头实现字符串(leetcode第208题):实现一个 Trie (前缀树),包含 insert, search, 和 startsWith 这三个操作。示例:
Trie trie = new Trie();
trie.insert(apple);
trie.search(apple); // 返回 true
trie.search(app); // 返回 false
trie.startsWith(app); // 返回 true
trie.insert(app);
trie.search(app); // 返回 true说明:你可以假设所有的输入都是由小写字母 a-z 构成的;保证所有输入均为非空字符串。
class Trie:
def __init__(self):
Initialize your data structure here.
self.root = {}
self.end_of_word = '#'
def insert(self, word: str) -> None:
Inserts a word into the trie.
node = self.root
for c in word:
node = node.setdefault(c, {})
node[self.end_of_word] = 1
def search(self, word: str) -> bool:
Returns if the word is in the trie.
node = self.root
for c in word:
if c not in node:
return False
node = node[c]
return self.end_of_word in node
def startsWith(self, prefix: str) -> bool:
Returns if there is any word in the trie that starts with the given prefix.
node = self.root
for c in prefix:
if c not in node:
return False
node = node[c]
return True上面是比较造轮子的一种方法,而在python里可以直接用字典来实现字典树
例题
单词搜索II
此题为leetcode第212题给定一个二维网格 board 和一个字典中的单词列表 words,找出所有同时在二维网格和字典中出现的单词。单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
思路:字典树+深度优先搜索
# 方向数组
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
# word结束标记
end_of_word = '#'
class Solution:
def findWords(self, board: List[List[str]], words: List[str]) -> List[str]:
if not board or len(board[0]) == 0 or len(words) == 0:
return []
self.res = set() # 结果保存在集合中
root = {} # 初始化根节点为空字典
# 对列表里的word构建字典树
for word in words:
node = root
# 这里的root将会是一个字典层层嵌套的结构。
# 如果c在node里,则取出键为c的值,如果不在,则在键c下新建空字典
for c in word:
node = node.setdefault(c, {})
node[end_of_word] = end_of_word # 标记word已结束
self.m, self.n = len(board), len(board[0])
# 遍历board,进行DFS
for i in range(self.m):
for j in range(self.n):
if board[i][j] in root:
self._dfs(board, i, j, '', root)
return list(self.res)
def _dfs(self, board, i, j, curr_word, curr_dict):
curr_word += board[i][j]
curr_dict = curr_dict[board[i][j]]
if end_of_word in curr_dict:
self.res.add(curr_word)
temp, board[i][j] = board[i][j], '*' # '*'表示暂时标记为已访问过
# 在(i, j)的4个方向上遍历
for k in range(4):
x, y = i + dx[k], j + dy[k]
# 如果x、y没有越界,并且没有被访问过,并且当前字母在curr_dict中
if 0 <= x < self.m and 0 <= y < self.n and board[x][y] != '*' and board[x][y] in curr_dict:
self._dfs(board, x, y, curr_word, curr_dict)
board[i][j] = temp # 恢复board[i][j]的值