递归
递归:在定义一个过程或函数时,出现本过程或本函数的成分称为递归。 递归条件:可以用递归解决的问题应该满足以下三个条件:
- 这个问题可以转化为一个或多个子问题来求解,而且这些子问题的求解方法与原问题完全相同
- 递归调用的次数是有限的
- 必须有终止条件
递归的底层原理: 函数调用操作包括从一块代码到另一块代码之间的双向数据传递和执行控制转移,大多数CPU使用栈来支持函数调用。单个函数调用操作所使用的的函数调用栈被称为栈帧。每次函数调用都会相应地创建一帧,返回函数地址、函数实参和局部变量值等,并将该帧压入调用栈。若该函数在返回之前又发生了新的调用,则将新函数对于的帧压入栈,成为栈顶。函数一旦执行完,对应的帧边出栈,控制权交给该函数的上层调用函数,并按照该帧保存的返回地址,确定程序中继续执行的位置。
递归问题一般解决步骤:
- 对问题$f(s_{n})$进行分析,假设出合理的小问题$f(s_{n-1})$
- 假设小问题$f(s_{n-1})$是可解的,在此基础上确定大问题$f(s_{n})$的解,即给出$f(s_{n})$与$f(s_{n-1})$之间的关系
- 确定一个特殊情况(如$f(s_{1})$或$f(s_{0})$的解),由此作为递归出口
时间复杂度: 时间复杂度$O(T)$通常是递归调用的数量(记作 $R$) 和计算的时间复杂度的乘积(表示为 $O(s)$)的乘积: $$ O(T)=R*O(s) $$
空间复杂度: 在计算递归算法的空间复杂度时,应该考虑造成空间消耗的两个部分:递归相关空间(recursion related space)和非递归相关空间(non-recursion related space)
代码模板:
def recursion(level, param1, param2, ...):
# 递归终止条件
if level > MAX_LEVEL:
return result
# 当前level的逻辑
process_data(level, data)
# 递归
self.recurison(level, param1, param2, ...)
# 如果必要的话,还原此层的状态
reverse_state(level)例题
两两交换链表中的节点
此题为leetcode第24题。示例:给定 1->2->3->4, 你应该返回 2->1->4->3。我们假设有一个链表,已经走到了中间某个节点,当前节点为head,这个一般情况可以表示如下:

我们希望head和next能够互换,希望达到如下效果:
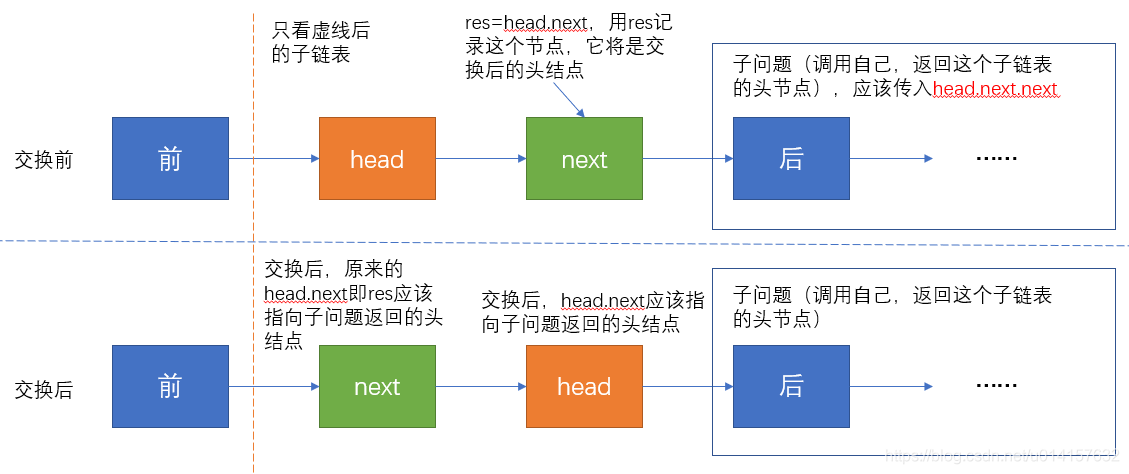
- 我们希望
head和next互换,互换后head指向后面,next变为当前子链表的头结点 - 交换后,
head应该指向后面的子链表,而后面的子链表应该是交换完成了的,也就是说,后面的子链表两两交换是个子问题,解决方式和当前的方式一样,所以这个子链表的头结点(即head.next.nex应该传入递归函数中) - 因为交换后
next为当前子链表的头结点,我们用一个指针指向它,即res=head.next,交换完后我们返回res即可,因为当前子链表也是上一层递归调用的子问题,我们要返回当前链表的头结点 - 交换的过程:首先我们需要将
head.next指向后面子问题返回的头结点,然后next指向head,即res.next=head - 交换完后,返回此时当前子链表的头结点
res即可 - 终止条件:当
head=None(无节点)或head.next=None(此时为最后一个节点)时,直接返回head
class Solution:
def swapPairs(self, head: ListNode) -> ListNode:
# 终止条件
if head == None or head.next == None:
return head
# 交换后的头结点
res = head.next
# 子问题递归,head指向子问题返回来的节点
head.next = self.swapPairs(head.next.next)
# next指向head
res.next = head
return res- 时间复杂度:$O(N)$,其中 $N$ 指的是链表的节点数量
- 空间复杂度:$O(N)$,递归过程中使用的堆栈空间
反转链表
此题为leetcode第206题。 示例:输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL假设我们有如下链表:
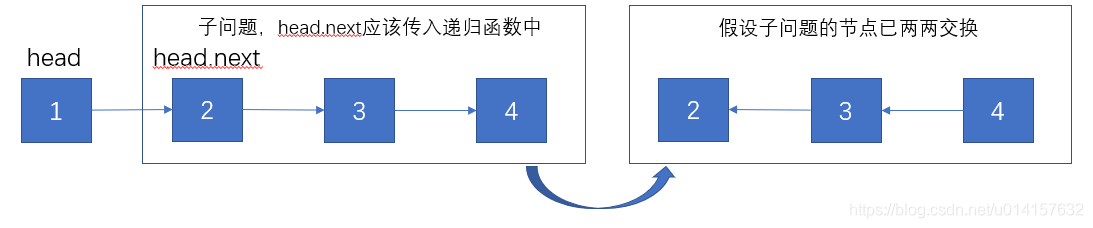
当前节点为head,假设子问题返回的链表已经两两反转,我们希望节点2能指向节点1,节点1指向None。递归过程如下图所示:
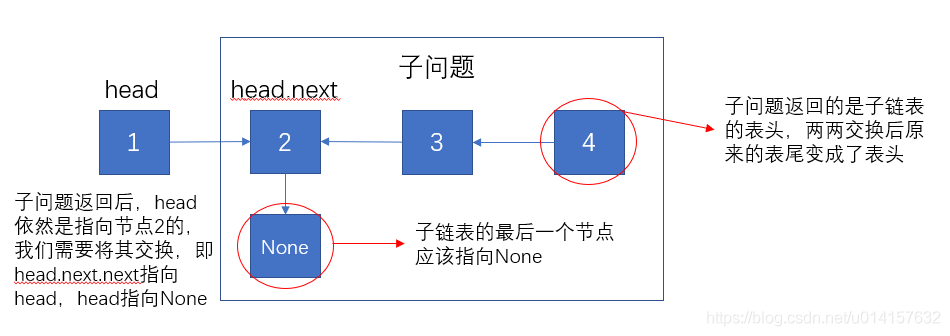
- 当前节点为
head,我们期望后续的子链表指向head,而head指向None。那么后续子链表的两两交换问题为子问题。 - 子问题里的子链表节点两两交换后,原来的尾节点(图中的节点4)变成了头结点,并且要返回这个头结点;原来的头结点(图中的节点2)变为了尾节点,并且要指向
None,因为尾节点最后都要指向None。注意此时head节点依然是指向节点2的,因为子问题并没有改变head的指向 - 交换过程:需要将节点2指向节点1,即
head.next.next=head,然后head指向None - 终止条件:
head=None(无节点)或head.next=None(最后一个节点)时,直接返回head
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
# 终止条件
if not head or not head.next:
return head
# 子问题递归,返回交换完后的子链表的头结点
res = self.reverseList(head.next)
# 交换
head.next.next = head
head.next = None
return res- 时间复杂度:$O(N)$,其中 $N$ 指的是链表的节点数量
- 空间复杂度:$O(N)$,递归过程中使用的堆栈空间
斐波那契数列
记忆化 此题为leetcode第509题。斐波那契数列有如下递归关系: $$ f(0)=0, f(1)=1 f(n)=f(n-1) + f(n-2),n>1 $$ 给定$n$计算$f(n)$。以计算$f(4)$为例,我们可以得到:$f(4)=f(3)+f(2)=f(2)+f(1)+f(1)+f(0)=f(1)+f(0)+f(1)+f(1)+f(0)$,把这个递归过程画出来如下图所示:
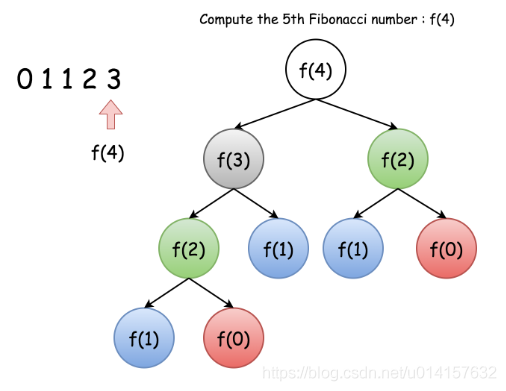
按说这个很容易找到子问题,并且终止条件也明确,但是我们观察发现,这其中有很多重复的计算,比如$f(2)$重复了两次,这会导致内存占用较多。为此,我们可以将中间结果暂存起来,到时候直接用就可以。
class Solution:
def fib(self, N: int) -> int:
# 缓存字典
catch = {}
def rec(N):
# 若N在缓存中,直接返回对应值
if N in catch:
return catch[N]
# N小于2时直接返回自己
if N < 2:
res = N
else:
res = rec(N-1) + rec(N-2)
# 放入缓存中
catch[N] = res
return res
return rec(N)- 时间复杂度:$O(N)$
- 空间复杂度:$O(N)$,缓存空间大小
注意这里我们使用了一个额外的函数rec(N),然后直接在fib函数中直接返回rec(N),我们称这样的递归为尾递归:尾递归函数是递归函数的一种,其中递归调用是递归函数中的最后一条指令。并且在函数中应该只有一次递归调用。 尾递归的好处是,它可以避免递归调用期间栈空间开销的累积,因为系统可以为每个递归调用重用栈中的固定空间。
合并两个有序链表
此题为leetcode第21题。示例:输入:1->2->4, 1->3->4 输出:1->1->2->3->4->4。我们假设有如下两个有序链表:
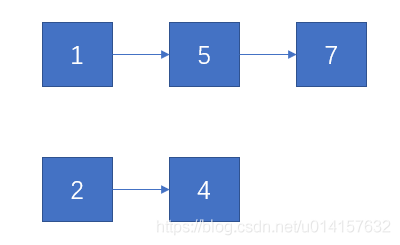
设l1指向了第一个链表中的某个位置,l2指向了第二个链表中的某个位置,我们比较这两个节点的大小。如果l1<l2,那么l1应该在l2之后,l2应该和l1之后的子链表继续比较,由此形成子问题。如果l1>l2,那么l2应该在l1之后,l1继续和l2之后的子链表比较。整个过程如下所示:
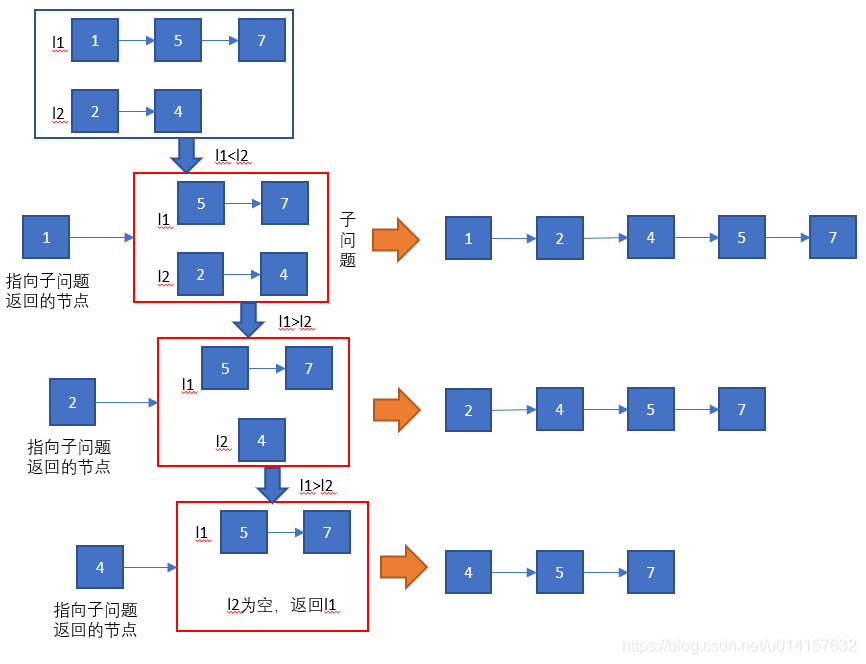
- 若
l1<l2,则将l1.next和l2传入递归函数中,将l1指向递归函数返回的节点;反之将l2.next和l1传入递归函数中,l2指向递归函数返回的节点。 - 当
l1=None时,说明l1已提前遍历完(或l1本来为空),l2剩下的也不用比较了,直接返回l2;同理l2=None时,直接返回l1。
class Solution:
def mergeTwoLists(self, l1, l2):
if l1 is None:
return l2
elif l2 is None:
return l1
elif l1.val < l2.val:
l1.next = self.mergeTwoLists(l1.next, l2)
return l1
else:
l2.next = self.mergeTwoLists(l1, l2.next)
return l2- 时间复杂度:$O(n + m)$。因为每次递归调用都会将指向
l1或l2的指针递增一次(逐渐接近每个列表末尾的 null),所以每个列表中的每个元素都会对mergeTwoLists进行一次调用。 因此,时间复杂度与两个列表的大小之和是线性相关的。 - 空间复杂度:$O(n + m)$。一旦调用
mergetwolist,直到到达l1或l2的末尾时才会返回,因此 $n + m$的栈将会消耗 $O(n + m)$ 的空间。
Pow(x, n)
此题为leetcode第50题
class Solution:
def myPow(self, x: float, n: int) -> float:
# 递归1
# def func(x, n):
# if n == 0:
# return 1
# if x == 0:
# return 0
# temp = func(x, n >> 1)
# # 位运算判断奇偶
# if n & 1: # n为奇数
# return temp * temp * x
# else: # n为偶数
# return temp * temp
# if n >= 0:
# res = func(x, n)
# else:
# res = 1 / func(x, -n)
# return res
# 递归2
# if n == 0:
# return 1
# if n < 0:
# return 1. / self.myPow(x, -n)
# if n % 2: # 如果n是奇数,在下一层算n/2
# return x * self.myPow(x, n - 1)
# else: # 如果n是偶数
# return self.myPow(x * x, n/2)
# 非递归
if n < 0:
x = 1. / x
n = -n
res = 1
while n:
if n & 1: # n为奇数
res *= x
x *= x
n >>= 1 # 右移一位,相当于n // 2
return res